
上位表示を狙いたいブログ初心者におすすめな方法は…あなたが狙ってる「キーワード」でGoogle検索して、上位10位までの記事の「タイトル、メタ情報、h2とh3」をエクセルにまとめる。それを比較すると…なんと!上位表示の「答え」が見つかる!ホント超おすすめの方法です!☺
— たかはし🍀ブログ×SEO (@jpnetkigyou) January 26, 2022
こちらは先日、たかはし🍀ブログ×SEOさん (@jpnetkigyou)が投稿されたツイートです。
今まで検索上位記事を分析する作業はしていなかったので、なるほど!このような分析作業もしないと!と同時にこれってGoogleスプレッドシートで割と簡単に出来そう!とも思いました。
という事で、「URLを入力すると、そのURLのタイトル、メタ情報(ディスクリプション)、H2とH3」を取得するスプレッドシートを作成してみました!
この記事では、上位表示できないというブログ初心者の方に、ライバルの記事情報が収集できるスプレッドシートを公開します。
やってる事は簡単なのでそれなりにパソコン慣れしている人からみたら当たり前かもですが、パソコンを触るのも不慣れなブログ初心者さんなら思いつかないかも?
こちらのスプレッドシートを使えば、ブログ初心者でも上位表示の答えが見つかりますよ!
公開したスプレッドシートのコピーの方法などは記事内で説明しますね!
目次
作成したスプレッドシート「記事情報取得シート」
このスプレッドシートで出来る事は、情報表示シートのB2セルに情報を取得したい記事のURLを入力すると、自動的にタイトル、メタ情報、H2とH3を取得してスプレットシートに表示します。
表示された情報はクリップボードへコピーして値の貼り付けをすれば、スプレッドシートやエクセルで使用する事が出来ます。
URLは毎回直接入力するだけでなく、URL管理シートで10個のURLを入力しておくと、情報表示シートのB2セルのプルダウンから選択出来ます。目視による簡易的な比較に使えるのではと考えています。
妥協した点
あくまで簡易チェックのスプレッドシートなので、いくつか妥協している点が有ります。
- H2、H3にコメントや関連記事などが出てきてしまう。
- H2+H3で500件まで。
- 見出し構成次第ではエラーとなってしまう。
件数は条件式書式の話なので、実際には500件以上余裕だと思います。H2、H3タグが500件以上あるサイトなんて見たくないしそんなのが競合だったら私なら即諦めちゃいますけど。
他は改善するのが大変そうなので諦めました。
とはいえ、上手くいかないケースは少ないと思いますので、データコピーの際に調整してもらえればと考えています。まぁこの辺は情報取得のサポートツールだと思ってフワッと使って頂けると嬉しいです。
また、今回はGoogleスプレッドシート専用の関数となるIMPORTXML関数を使用しています。
便利な関数では有りますが、
- エクセルでは使用出来ない。
- 読み込み中のままとなってしまうケースがある。
といった事もあります。読み込み中の場合は、まずは焦らず、しばらく待つ。それでもダメな場合はキャッシュのクリアを実施してみて下さい。

公開スプレッドシートをコピーして使用する方法
まず大前提として、スプレッドシートを作業出来るGoogleアカウントを用意して下さい!
そのGoogleアカウントにログインした状態で、当記事の公開スプレッドシートを開いて下さい。
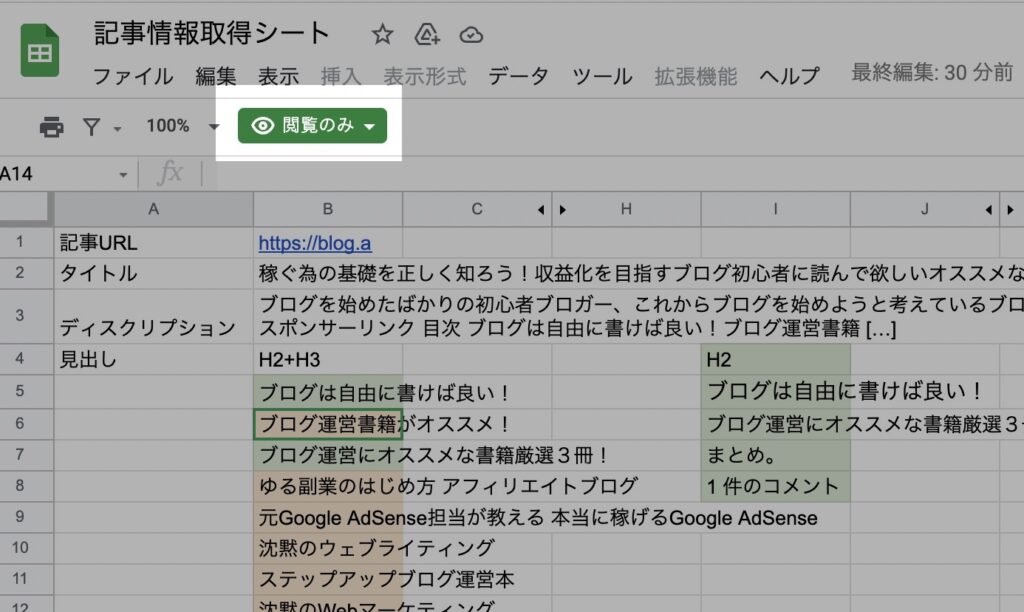
開いたスプレッドシートは閲覧権限しかありませんので、見ることはできますが、編集する事が出来ません。
このままでは使い道がないので・・・
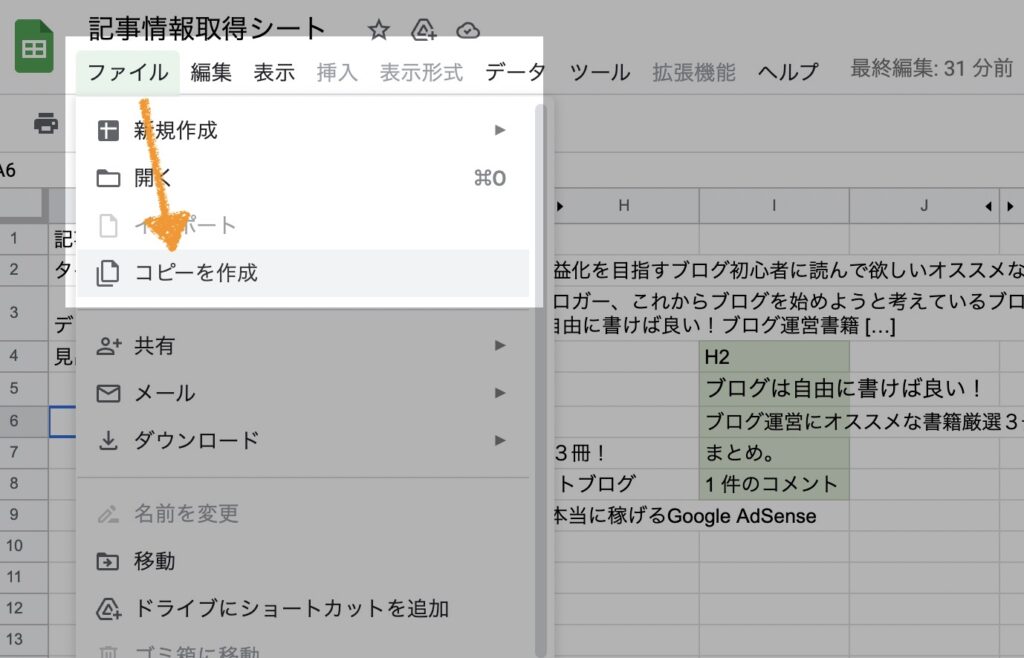
ファイル→コピーを作成するを選択し、
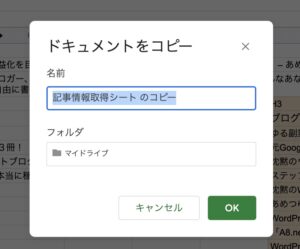
ポップアップウィンドウでコピーされるスプレッドシートの名前を決定してOKを選択すると・・・
コピー作成されたスプレッドシートが開きます!
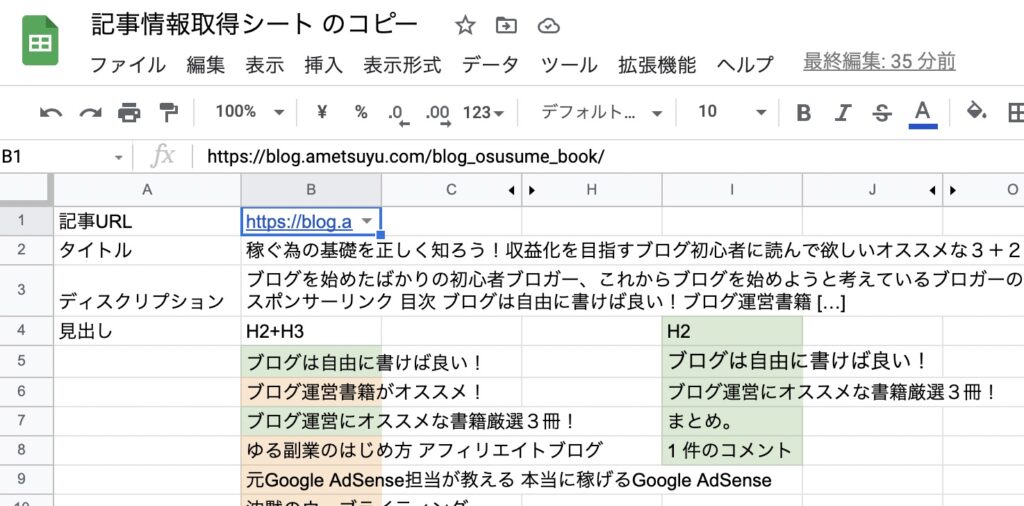
あとは自由に編集出来ますので、情報表示シートのB1セルに情報を取得したいURLを入力して下さい。
また、URL管理シートを開いて、B列に情報を取得したいURLを入力し、入力した10件のURLを情報表示シートのB1セルでプルダウンで選択する事も可能です。
(URL管理シートのC列の記事タイトルは自動的に取得します。)
Google検索結果の上位10件のURLを入力して・・・
スクレイピングが禁止されていなくて、気になっているサイトのURLを入力して情報を取得してみて下さい!
作成したスプレッドシートの解説。
今回はほとんど、IMPORTXML関数です。
IMPORTXML関数は指定したURLから様々な情報を取得する事が出来る関数です。
タイトル、メタ情報取得についてはpusy.tokyoさんの記事を参考にさせて頂きました。
タイトル取得
タイトルを取得するB2セルの数式
=INDEX(IMPORTXML(B1,"//title"),1,1)実際にタイトルを取得する関数は
=IMPORTXML(B1,"//title")この関数で、B1セルに入力されているURLのtitleタグの情報を取得します。
サイトの構成によってはtitleタグが複数有り、結果が配列となる可能性があるので、
=INDEX(タイトル情報,1,1)INDEX関数で配列の1番最初を持ってくるようにしてあります。
メタ情報(ディスクリプション)取得
メタ情報(ディスクリプション)を取得するB3の数式
=IFNA(IMPORTXML(B1,"//meta[@name='description']/@content"),"- 指定なし -")こちらも実際に情報を取得するのは・・・
=IMPORTXML(B1,"//meta[@name='description']/@content")この関数で、B1セルに入力されているURLの情報を取得します。
メタ情報は設定していないサイトも多いので、上手く情報が取れなかった時の為に・・・
=IFNA(メタ情報,"- 指定なし -")IFNA関数は数式の結果が#N/Aエラーとなった場合に制御するIF分です。
今回で言うとメタ情報が取得出来ず、#N/Aエラーとなった場合に– 指定なし –と表示する数式になります。
H2タグ&H3タグ情報取得
見出し情報を取得するB5の数式
(ちなみにB4、I4、P4は取得する情報に対する見出しになります。)
=IMPORTXML(B1,"//h2 | //h3")この関数で、B1セルに入力されているURLの見出し情報を取得します。
H2とH3の情報をまとめて書き出すのですが・・・混在しているとわかりにくにので、I列、P列で同じような数式でH2の情報、H3の情報を書き出しています。
その上で、条件付き書式でB列の取得した見出しをI列、P列で一致した場合に色付けをしてわかりやすくしています。
おわりに。
本当はキーワードをセルに入力してGoogle検索結果を取得する数式も考えていたのですが、Googleはスクレイピング禁止な上、取得出来ないように技術的にブロックされているみたいです。
Google検索結果を取得するためにはGASでAPIを使って取得する必要があるようです。
ちょっと調べた感じではそこまで難しくなさそうなので、後日作ってみようと思いますが、1日あたりのAPIの取得可能件数の問題もあってその機能を組み込んだスプレッドシートの公開は出来なそうです。
方法をまとめた記事ぐらいは作成しようと思いますので、その時には追記します!
Googleスプレッドシートとエクセルの関数の違いについて⇗
Googleスプレッドシート専用関数を使った例
ArrayFormula関数⇗GoogleTranslate関数⇗ImportXml関数⇗
エクセルでも可能
Google Apps Script(GAS)との組み合わせ

追記:記事分析AIサービス「Tracky(トラッキー)」
Trackyというサービスをリリースしました!
— ウマたん@スタビジ(データサイエンス×ビジネス) (@statistics1012) January 31, 2022
まだ全然β版なんですが、URLとキーワードを入れると記事の改善点を教えてくれる記事分析AIサービスです。
フィードバックをガンガン取り入れて改善していくつもりなので是非使ってみてくださーい。フィードバックください!https://t.co/iTIkJLSRqA
2022/1末にリリースされたサービスです。
キーワードとURLを入れると文字数やタグの数などで改善点をAIが記事分析してくれるサービスとの事。
上で紹介しているスプレッドシートの発展版で、技術がある人が作るとこんなサービスになるのかぁと思ったのですが、少し使ってみた感じ似てるんですが出来る事は少し違うようでした。
ですので、二つを組み合わせるとより記事分析が簡単になるのでは?と感じました!
リリース時点では完全無料のようですので、こちらも駆使して記事を分析してリライトして下さい!